Entrada anterior: La ingeniería detrás de Netflix (Parte I)
A medida que la producción de Netflix Originals crece cada año, también lo hace nuestra necesidad de crear aplicaciones que permitan la eficiencia durante todo el proceso creativo. Nuestra Organización de Ingeniería de Estudio más amplia ha creado numerosas aplicaciones que ayudan a que el contenido avance desde la presentación (también conocido como el guión) hasta la reproducción: desde la adquisición de contenido del guión, las negociaciones de acuerdos y la gestión de proveedores hasta la programación, la optimización de los flujos de trabajo de producción, etc.
Altamente integrado desde el principio
Hace aproximadamente un año, nuestro equipo de Studio Workflows comenzó a trabajar en una nueva aplicación que atraviesa múltiples dominios del negocio. Teníamos un desafío interesante en nuestras manos: necesitábamos construir el núcleo de nuestra aplicación desde cero, pero también necesitábamos datos que existían en muchos sistemas diferentes.
Algunos de los puntos de datos que necesitábamos, como datos sobre películas, fechas de producción, empleados y ubicaciones de filmación, se distribuyeron en muchos servicios que implementan varios protocolos: gRPC, JSON API, GraphQL y más. Los datos existentes fueron cruciales para el comportamiento y la lógica empresarial de nuestra aplicación. Necesitábamos estar altamente integrados desde el principio.
Fuentes de datos intercambiables
Una de las primeras aplicaciones para dar visibilidad a nuestras producciones se construyó como un monolito. El monolito permitió un desarrollo rápido y cambios rápidos mientras que el conocimiento del espacio era inexistente. En un momento, más de 30 desarrolladores estaban trabajando en él y tenía más de 300 tablas de base de datos.
Con el tiempo, las aplicaciones evolucionaron de una amplia oferta de servicios a ser altamente especializadas. Esto resultó en la decisión de descomponer el monolito en servicios específicos. Esta decisión no se basó en problemas de rendimiento, sino en establecer límites alrededor de todos estos dominios diferentes y permitir que los equipos dedicados desarrollen servicios específicos de dominio de forma independiente.
El monolito aún proporcionaba grandes cantidades de los datos que necesitábamos para la nueva aplicación, pero sabíamos que el monolito se rompería en algún momento. No estábamos seguros del momento de la ruptura, pero sabíamos que era inevitable y necesitábamos estar preparados.
Por lo tanto, podríamos aprovechar algunos de los datos del monolito al principio, ya que todavía era la fuente de la verdad, pero prepárese para intercambiar esas fuentes de datos por nuevos microservicios tan pronto como estén en línea.
Aprovechamiento de la arquitectura hexagonal
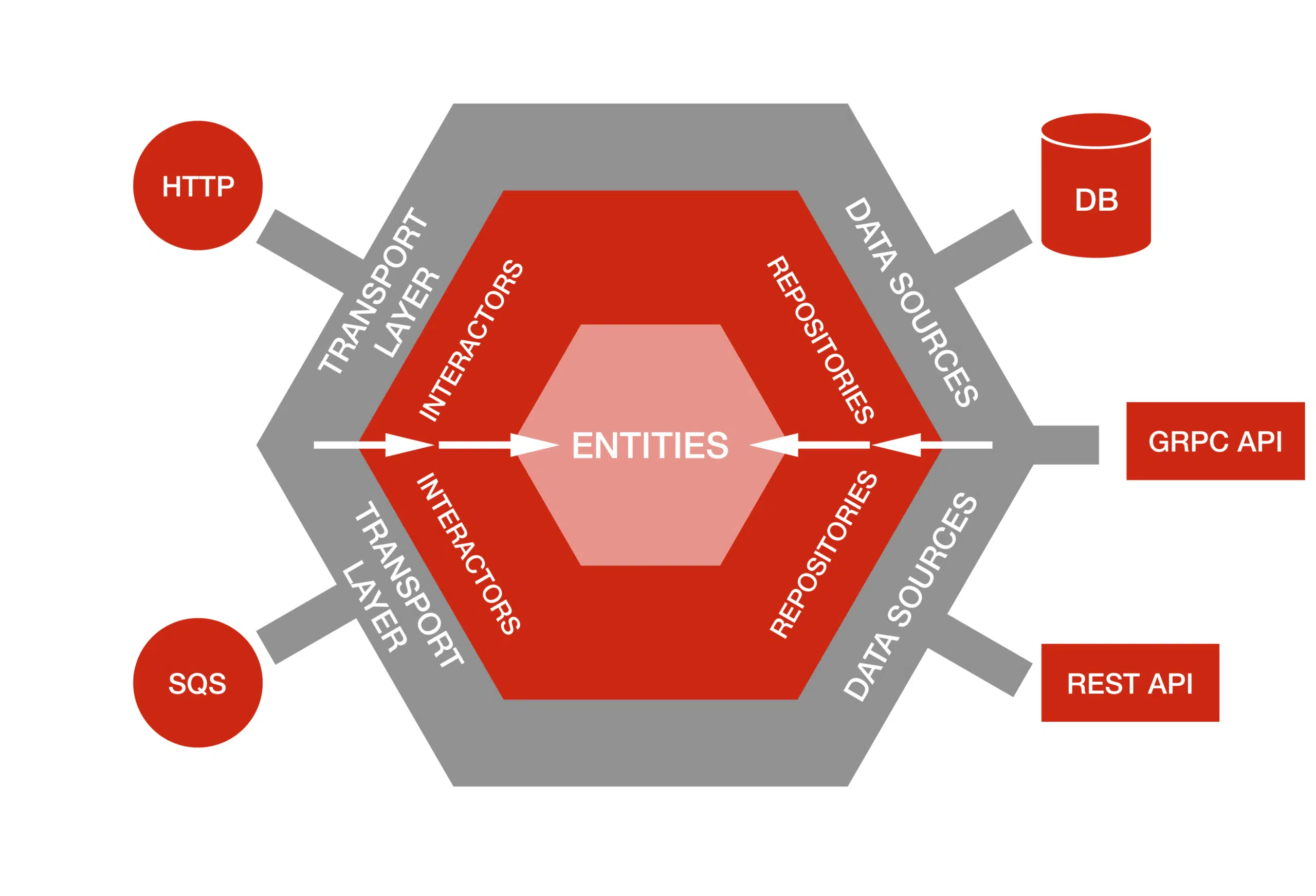
Necesitábamos admitir la capacidad de intercambiar fuentes de datos sin afectar la lógica empresarial, por lo que sabíamos que teníamos que mantenerlas desacopladas. Decidimos construir nuestra aplicación basándonos en los principios detrás de la Arquitectura Hexagonal.
La idea de la Arquitectura Hexagonal es poner entradas y salidas en los bordes de nuestro diseño. La lógica empresarial no debe depender de si exponemos una API REST o GraphQL, y no debe depender de dónde obtenemos los datos: una base de datos, una API de microservicio expuesta a través de gRPC o REST, o simplemente un simple archivo CSV.
El patrón nos permite aislar la lógica central de nuestra aplicación de preocupaciones externas. Tener nuestra lógica central aislada significa que podemos cambiar fácilmente los detalles de la fuente de datos sin un impacto significativo o reescrituras importantes de código en la base de código.
Una de las principales ventajas que también vimos en tener una aplicación con límites claros es nuestra estrategia de prueba: la mayoría de nuestras pruebas pueden verificar nuestra lógica empresarial sin depender de protocolos que pueden cambiar fácilmente.
Definiendo los conceptos centrales
Aprovechados de la Arquitectura Hexagonal, los tres conceptos principales que definen nuestra lógica empresarial son Entidades , Repositorios e Interactores .
- Las entidades son los objetos del dominio (por ejemplo, una película o un lugar de filmación); no tienen conocimiento de dónde se almacenan (a diferencia de Active Record en Ruby on Rails o la API de persistencia de Java).
- Los repositorios son las interfaces para obtener entidades, así como para crearlas y cambiarlas. Mantienen una lista de métodos que se utilizan para comunicarse con las fuentes de datos y devuelven una sola entidad o una lista de entidades. (por ejemplo, UserRepository). https://martinfowler.com/eaaCatalog/repository.html
- Los interactores son clases que organizan y realizan acciones de dominio; piense en objetos de servicio o de casos de uso. Implementan reglas comerciales complejas y lógica de validación específicas para una acción de dominio (por ejemplo, incorporación de una producción)
Con estos tres tipos principales de objetos, podemos definir la lógica empresarial sin ningún conocimiento o cuidado de dónde se guardan los datos y cómo se activa la lógica empresarial. Fuera de la lógica empresarial están las fuentes de datos y la capa de transporte:
- Las fuentes de datos son adaptadores para diferentes implementaciones de almacenamiento.
Una fuente de datos puede ser un adaptador a una base de datos SQL (una clase Active Record en Rails o JPA en Java), un adaptador de búsqueda elástica, API REST o incluso un adaptador a algo simple como un archivo CSV o un Hash. Una fuente de datos implementa métodos definidos en el repositorio y almacena la implementación de la obtención y envío de datos. - La capa de transporte puede activar un interactor para realizar la lógica empresarial. Lo tratamos como una entrada para nuestro sistema. La capa de transporte más común para microservicios es la capa de API HTTP y un conjunto de controladores que manejan solicitudes. Al extraer la lógica de negocios en interactores, no estamos acoplados a una capa de transporte o implementación de controlador en particular. Los interactores pueden ser activados no solo por un controlador, sino también por un evento, un trabajo cron o desde la línea de comando.
 2")
Fuente: https://netflixtechblog.com/
Con una arquitectura de capas tradicional, tendríamos todas nuestras dependencias apuntando en una dirección, cada capa de arriba dependiendo de la capa de abajo. La capa de transporte dependería de los interactores, los interactores dependerían de la capa de persistencia.
En la Arquitectura Hexagonal, todas las dependencias apuntan hacia adentro: nuestra lógica empresarial central no sabe nada sobre la capa de transporte o las fuentes de datos. Aún así, la capa de transporte sabe cómo utilizar los interactores y las fuentes de datos saben cómo ajustarse a la interfaz del repositorio.
Con esto, estamos preparados para los cambios inevitables en otros sistemas Studio y, cuando sea necesario, la tarea de intercambiar fuentes de datos es fácil de lograr.
Intercambio de fuentes de datos
La necesidad de intercambiar fuentes de datos llegó antes de lo que esperábamos: de repente, alcanzamos una restricción de lectura con el monolito y tuvimos que cambiar una determinada lectura para una entidad a un microservicio más nuevo expuesto sobre una capa de agregación GraphQL. Tanto el microservicio como el monolito se mantuvieron sincronizados y tenían los mismos datos, la lectura de un servicio u otro produjo los mismos resultados.
Logramos transferir lecturas de una API JSON a una fuente de datos GraphQL en 2 horas.
La principal razón por la que pudimos lograrlo tan rápido se debió a la arquitectura hexagonal. No permitimos que ningún detalle de persistencia se filtrara a nuestra lógica empresarial. Creamos una fuente de datos GraphQL que implementó la interfaz del repositorio. Un simple cambio de una línea era todo lo que necesitábamos para comenzar a leer desde una fuente de datos diferente.
 3")
Fuente: https://netflixtechblog.com/
En ese momento, sabíamos que la Arquitectura Hexagonal funcionaba para nosotros.
La gran parte de un cambio de una sola línea es que mitiga los riesgos del lanzamiento. Es muy fácil revertir en el caso de que un microservicio descendente fallara en la implementación inicial. Esto también nos permite desacoplar la implementación y la activación, ya que podemos decidir qué fuente de datos usar a través de la configuración.
Ocultar detalles de la fuente de datos
Una de las grandes ventajas de esta arquitectura es que podemos encapsular los detalles de implementación de la fuente de datos. Nos encontramos con un caso en el que necesitábamos una llamada a la API que aún no existía: un servicio tenía una API para obtener un solo recurso, pero no tenía implementada una búsqueda masiva. Después de hablar con el equipo que proporciona la API, nos dimos cuenta de que este punto de conexión tardaría algún tiempo en entregarse. Así que decidimos seguir adelante con otra solución para resolver el problema mientras se construía este punto final.
Definimos un método de repositorio que tomaría múltiples recursos dados múltiples identificadores de registro, y la implementación inicial de ese método en la fuente de datos envió múltiples llamadas simultáneas al servicio descendente. Sabíamos que esta era una solución temporal y que la segunda toma en la implementación de la fuente de datos era usar la API masiva una vez implementada.
 4")
Un diseño como este nos permitió avanzar en la satisfacción de las necesidades comerciales sin acumular mucha deuda técnica o la necesidad de cambiar la lógica comercial posteriormente.
Estrategia de prueba
Cuando comenzamos a experimentar con la Arquitectura Hexagonal, sabíamos que teníamos que idear una estrategia de prueba. Sabíamos que un requisito previo para una gran velocidad de desarrollo era tener un conjunto de pruebas que fuera confiable y súper rápido. No pensamos en ello como algo agradable, sino imprescindible.
Decidimos probar nuestra aplicación en tres capas diferentes:
- Probamos nuestros interactores, donde vive el núcleo de nuestra lógica empresarial pero es independiente de cualquier tipo de persistencia o transporte. Aprovechamos la inyección de dependencia y nos burlamos de cualquier tipo de interacción del repositorio. Aquí es donde nuestra lógica empresarial se prueba en detalle , y estas son las pruebas que nos esforzamos por tener.
 5")
- Probamos nuestras fuentes de datos para determinar si se integran correctamente con otros servicios, si se ajustan a la interfaz del repositorio y verificamos cómo se comportan ante los errores. Intentamos minimizar la cantidad de estas pruebas.
 6")
- Tenemos especificaciones de integración que abarcan toda la pila, desde nuestra capa de transporte / API, a través de los interactores, repositorios, fuentes de datos y servicios posteriores. Estas especificaciones prueban si “conectamos” todo correctamente. Si una fuente de datos es una API externa, llegamos a ese punto final y registramos las respuestas (y las almacenamos en git), lo que permite que nuestro conjunto de pruebas se ejecute rápidamente en cada invocación posterior. No realizamos una amplia cobertura de pruebas en esta capa, generalmente solo un escenario de éxito y un escenario de falla por acción de dominio.
 7")
No probamos nuestros repositorios, ya que son interfaces simples que implementan las fuentes de datos, y rara vez probamos nuestras entidades, ya que son objetos simples con atributos definidos. Probamos las entidades si tienen métodos adicionales (sin tocar la capa de persistencia).
Tenemos margen de mejora, como no hacer ping a ninguno de los servicios en los que confiamos, sino confiar al 100% en las pruebas de contrato. Con un conjunto de pruebas escrito de la manera anterior, logramos ejecutar alrededor de 3000 especificaciones en 100 segundos en un solo proceso.
Es maravilloso trabajar con un conjunto de pruebas que se puede ejecutar fácilmente en cualquier máquina, y nuestro equipo de desarrollo puede trabajar en sus funciones diarias sin interrupciones.
Retrasar decisiones
Estamos en una excelente posición cuando se trata de intercambiar fuentes de datos a diferentes microservicios. Uno de los beneficios clave es que podemos retrasar algunas de las decisiones sobre si queremos almacenar datos internos en nuestra aplicación y cómo. Según el caso de uso de la función, incluso tenemos la flexibilidad de determinar el tipo de almacén de datos, ya sea relacional o de documentos.
Al comienzo de un proyecto, tenemos la menor cantidad de información sobre el sistema que estamos construyendo. No debemos encerrarnos en una arquitectura con decisiones desinformadas que conducen a una paradoja del proyecto: tomar las decisiones más importantes cuando el conocimiento está en su nivel más bajo.
Las decisiones que tomamos ahora tienen sentido para nuestras necesidades y nos han permitido actuar con rapidez. La mejor parte de la Arquitectura Hexagonal es que mantiene nuestra aplicación flexible para los requisitos futuros.
Traducción al español: Juan José González Faúndez
por Damir Svrtan y Sergii Makagon
Fuente: https://netflixtechblog.com/ready-for-changes-with-hexagonal-architecture-b315ec967749