Amazon nos provee una serie de servicios interesantes para construir arquitecturas basadas en microservicios: Lambda, EC2 con VPC y Fargate (para trabajar con contenedores y Kubernetes), comúnmente denominado ECS (Amazon Elastic Container Service).
En este artículo me centraré en explicar el funcionamiento de Lambda a través de un ejemplo concreto y cómo nos podría ayudar a migrar aplicaciones monolíticas en sendas plataformas en la nube basadas en arquitecturas de microservicios.
Un poco de teoría (que siempre ayuda)
Lambda se basa en un concepto de computación en la nube denominado Serverless. ¿qué significa esto?
Básicamente Serverless es sin servidor. El serverless computing o la arquitectura serverless es un modelo en la nube que permite a los usuarios crear y ejecutar aplicaciones y procesos sin entrar en contacto con el servidor. Por lo tanto, a pesar de su denominación, estos entornos en la nube también cuentan con servidores, con la diferencia de que es el proveedor (Amazon en este caso) el que se encarga de suministrarlo, gestionarlo y escalarlo. Serverless es parte de lo que se conoce como Plataformas como Servicios (PaaS).
La ventaja de este tipo de arquitectura en la nube es evidente, nos permite centrarnos en el desarrollo del producto y la ejecución del software, más que en la infraestructura capaz de soportar este desarrollo. Podemos ponerle más atención a la lógica de negocios de nuestra aplicación, sin embargo, desde el mismo código debemos agregar instrucciones adicionales como las funciones sin estado y todas aquellas instrucciones acerca de cómo debe reaccionar un programa a determinados eventos. Debido precisamente al papel esencial que juegan las funciones, hay proveedores que ofrecen sus servicios serverless bajo el nombre “Function as a Service (FaaS)” y acá es donde entra Lambda de Amazon AWS.
Los proveedores de serverless computing no solo son los responsables de que los recursos de servidor necesarios estén siempre disponibles, sino también de garantizar el mayor nivel de seguridad y alta disponibilidad posible. Por norma general, estos servicios suelen facturarse según el modelo de pago por uso o Pay per Use, de manera que los clientes solo tienen que pagar por los servicios de los que de hecho han disfrutado.
https://aws.amazon.com/es/serverless/
Microservicios con Lambda

El patrón de arquitectura de microservicio no está vinculado a la arquitectura típica de tres capas (3 tiers); sin embargo, este patrón popular puede obtener importantes beneficios del uso de recursos sin servidor.
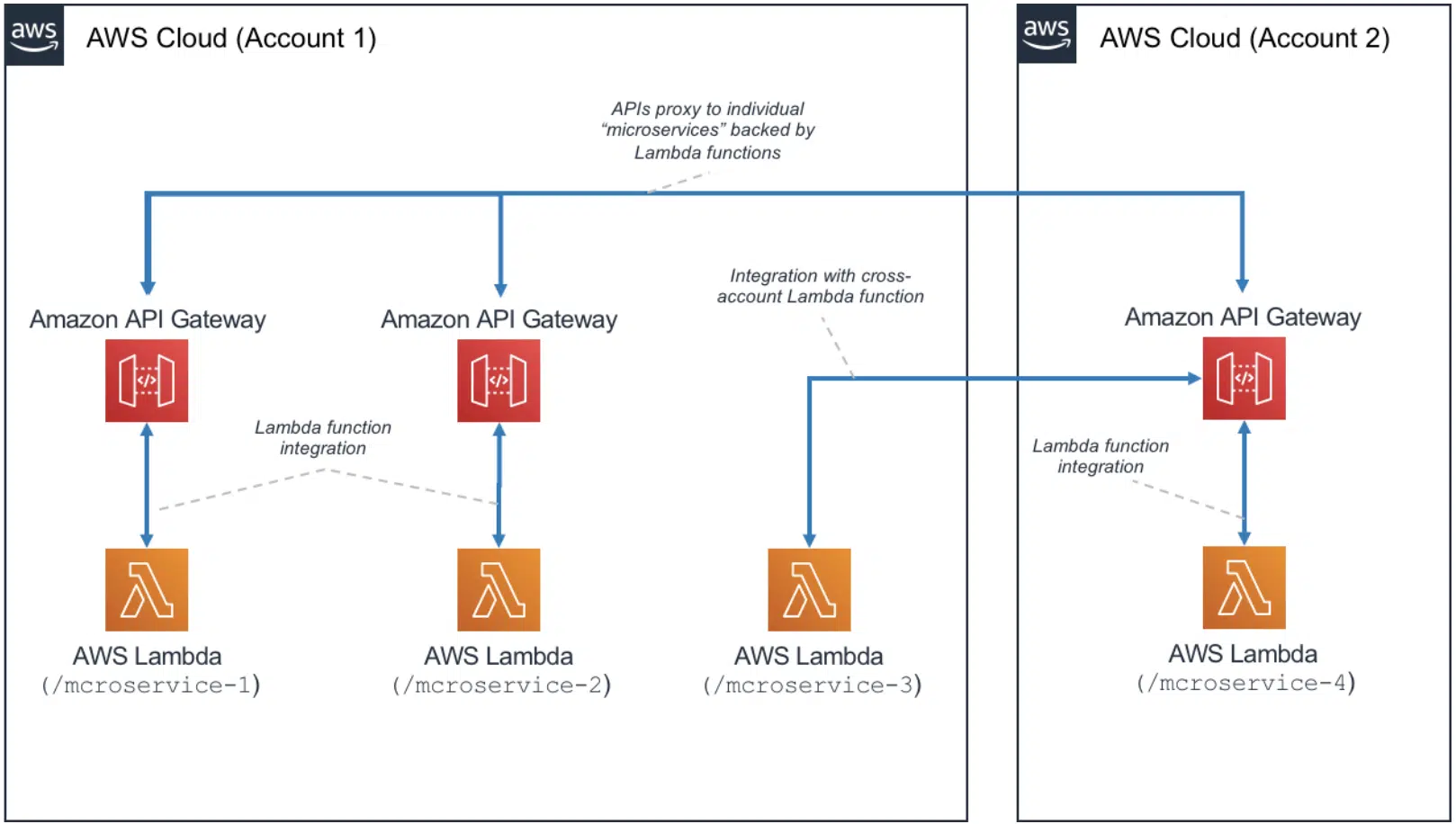
En esta arquitectura, cada uno de los componentes de la aplicación se desacopla y se implementa y opera de forma independiente. Una API creada con Amazon API Gateway y funciones ejecutadas posteriormente por AWS Lambda es todo lo que necesita para construir un microservicio. El equipo de desarrollo es libre de utilizar estos servicios para desacoplar y fragmentar su entorno al nivel de granularidad deseado.
En general, un entorno de microservicios puede presentar las siguientes dificultades: sobrecarga repetida para crear cada nuevo microservicio, problemas con la optimización de la densidad / utilización del servidor, complejidad de ejecutar múltiples versiones de múltiples microservicios simultáneamente y proliferación de requisitos de código del lado del cliente para integrar los servicios de forma separada.
Cuando se crean microservicios utilizando recursos sin servidor, estos problemas se vuelven más fáciles de resolver y, en algunos casos, simplemente desaparecen. El patrón de microservicios sin servidor reduce la barrera para la creación de cada microservicio posterior (Amazon API Gateway incluso permite la clonación de API existentes y el uso de funciones Lambda en otras cuentas -tal y como se aprecia en la imagen-). La optimización de la utilización del servidor ya no es relevante con este patrón de arquitectura.
Manos a la obra
Las herramientas que utilizaremos serán las siguientes:
- Pueden trabajar en Windows, Mac o Linux (en mi caso estoy en Mac)
- Cuenta Amazon AWS (link de registro: https://aws.amazon.com/es/free/)
- Node JS (versión que yo utilizo es la v14.16.1)
- Serverless Framework (https://www.serverless.com/)
NOTA: se deben tener conocimiento básicos y medios de como trabajar con Amazon AWS
Los pasos necesarios para completar la configuración antes de comenzar a desarrollar el servicio de prueba son los siguientes:
- Toda vez creada la cuenta de Amazon debemos crear un perfil con permisos de administración, para esto debemos ir a las sección de cuentas IAM y crear un usuario asociado a la política AdministratorAccess. En mi caso yo he creado el siguiente usuario (juanjo.lambda):

Poner atención a las credenciales de seguridad porque son las que se utilizarán al momento de configurar el framework de AWS en Node.
2. cuando ya tenemos la cuenta creada podemos ir a instalar y configurar Serverless en nuestra máquina, para esto ejecutamos el siguiente comando node:

Comprobando la versión:

3. Creando un proyecto Node.js con el Framework Serverless
Primero crearemos un directorio de trabajo y luego el comando para crear la estructura base del proyecto


Se creará un proyecto serverless usando el template de AWS y Node.js, en un directorio llamado cliente-service y cuyo archivo donde manejaremos los eventos tendrá el nombre cliente.


Los archivos que encontraremos en este directorio son:
- .npmignore: Este archivo es usado para decirle a npm cuales archivos deberían estar fuera del paquete. Parecido al .gitignore de GIT.
- handler.js: En este archivo se declarará la función Lambda.
- serverless.yml: Este archivo declara la configuración que el Serverless Framework usa para crear el servicio. serverless.yml tiene 3 secciones: provider, functions, y resources.
- provider: Esta sección declara la configuración específica del proveedor cloud que usaremos. Se puede especificar el nombre, la región, el runtime a usar, entre otros.
- functions: Esta sección se utiliza para especificar todas las funciones que componen el servicio. Un servicio puede estar compuesto por una o más funciones.
- resources: Esta sección declara todos los recursos que utilizan las funciones. Los recursos se declaran mediante AWS CloudFormation.
De ahora en más continuaremos usando Visual Studio Code
4. Vamos a actualizar el archivo serverless.yml agregándole alguna funcionalidad para que el servicio cliente vaya tomando forma.

service: cliente
Corresponde al nombre del servicio, tiene que ser único para la cuenta en la cuál estamos trabajando. Corresponde al –name cuando creamos el proyecto.
farmeworkVersion: ‘2’
Versión del framework o rango de versiones a usar y que estén soportadas por este servicio. Corresponde al Framework Core de la instalación.
provider:
Configuración definida del proveedor de la nube. Como usamos AWS, definimos la configuración correspondiente de AWS. runtime: versión de Node usada para levantar el proyecto. stage: etapa en la que nos encontramos, dev = desarrollo. region: zona de disponibilidad de Amazon en la que vamos a desplegar el servicio, en este caso us-east-2 (Ohio).
functions:
Finalmente, definimos la función clienteSubmission. En la configuración que se muestra arriba, declaramos que cuando se realiza la solicitud HTTP POST a / clientes, se debe invocar el controlador api/cliente.submit. También especificamos la memoria que queremos asignar a la función.
5. Ahora creamos el directorio donde pondremos las api, el archivo handler.js lo moveremos a este directorio api y cambiaremos el nombre del archivo de handler.js a cliente.js

6. Ahora vamos a agregar la lógica submit a nuestro servicio dentro del archivo cliente.js

7. Hacemos deploy del servicio a Lambda


¿En qué momento supo el framework Serverless que debía conectarse a cierta cuenta de Amazon AWS?
En mi caso ya lo tenía configurado, pero cuando ustedes lo ejecuten por primera vez les pedirá las credenciales del usuario que creamos al inicio de este artículo.
¿Qué hizo el Framework en todo este proceso?
- Empaquetó el servicio lo que significa que pasó por un proceso de Build para la comprobación de errores de compilación.
- Excluyó las dependencia de desarrollo
- Comienza la creación del Stack en Amazon
- Sube el archivo de CloudFormation a un bucket de S3
- Sube todos los artefactos del proyecto (servicio comprimido) al bucket de S3
- Valida el template del servicio
- Crea el servicio en Lambda
- Crea la API Gateway de este servicio que es la encargada de entregarnos el EndPoint del servicio
8. Probamos el servicio usando CURL usando la URL del EndPoint que nos creó automáticamente API Gateway
curl -H “Content-Type: application/json” -X POST https://tzym9tibcg.execute-api.us-east-2.amazonaws.com/dev/clientes
Y voalá!

Veamos todo este paso a paso directo en Amazon AWS



Y todo esto lo hicimos a puro código, sin tocar en ningún momento ningún servidor, menos un sistema operativo y las configuraciones fueron básicas. Nosotros simplemente realizamos el deploy y Amazon AWS se encarga del resto. Ellos nos proveen toda la plataforma y podemos de esta forma ir creando nuevos servicios o funciones dentro del archivo cliente.js para ejecutar otras tareas, como por ejemplo conectarse a algún RDS o motor de base de datos, rescatar información desde alguna tabla basada en NoSQL, conectarse con otros servicios, etc, etc.
Recomendación: borrar los bucket de S3, las API Gateway, los servicios Lambda y todos los registros del CloudWatch que el servicio pudo haber creado luego de ejecutar la prueba para que no entren en gastos adicionales.
Espero que el artículo sea de utilidad porque considero que las plataformas en la nube irán creciendo cada vez más y ofreciendo más servicios como estos que son de utilidad para arquitectos y desarrolladores de software, sobre todo aquellos productos cuyo delivery sea utilizando modelos de distribución como SaaS (Software As A Service).
En la medida de lo posible iré escribiendo más artículos relacionados con Amazon AWS. En una entrega futura me centraré en otra forma de definir arquitecturas de microservicios pero sin usar Lambda, sino que directamente a través de una VPC (Virtual Private Cloud) con sus propias instancias EC2, donde ya manejaremos conceptos como el de balanceo de carga (ELB) y grupos de auto-escalamiento, de forma tal de poder asegurar sistemas con características de alta disponibilidad y alta escalabilidad.
Nos vemos en la próxima entrega
Juan José González F. es un consultor independiente de la empresa I2J Consultoría IT y actualmente me dedico a prestar servicios a empresas de software u otras que deseen mejorar sus sistemas desde la perspectiva de la arquitectura de plataformas o software. Poniendo foco en la integración de sistemas que requieran de una alta disponibilidad y escalabilidad principalmente utilizando tecnologías en la nube como Amazon AWS.