Clean Architecture es un patrón de Arquitectura de Software creado por Robert C. Martin quien también propuso los principios SOLID.
Un patrón de arquitectura de software es una estructura o esquema de organización esencial para un sistema de software, consta de subsistemas, responsabilidades e interrelaciones. Dentro de los patrones más conocidos tenemos: 3 capas, microservicios, patrón hexagonal, dirigida por eventos, SOA (orientada a servicios), MVC, MVVM, etc.-
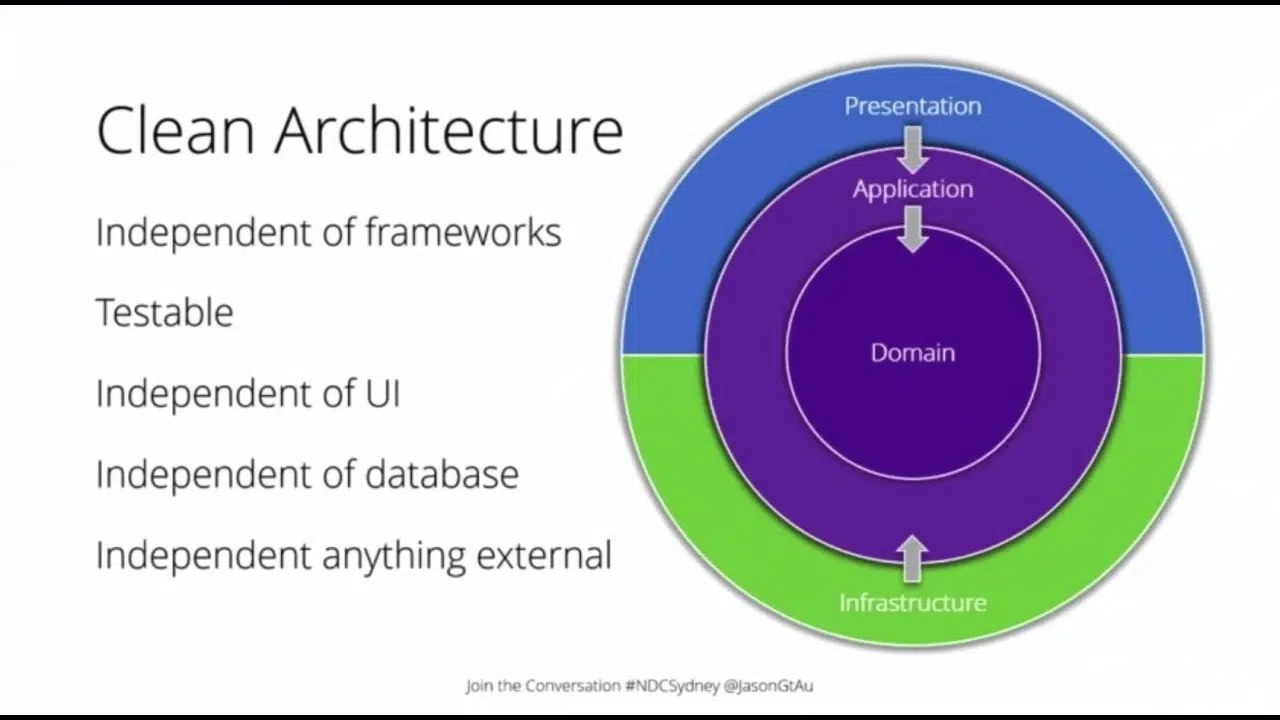
¿Cuáles son los principios que guían a Clean Architecture?
Independencia de cualquier framework
La arquitectura limpia debe poder aplicarse a cualquier sistema, independientemente del lenguaje de programación o las bibliotecas/frameworks que utilice. Las capas deben estar tan bien separadas que puedan sobrevivir individualmente, sin necesidad de elementos externos.
Testeable
Cuanto más pura y atómica sea una función, clase o módulo (es decir, sin efectos secundarios), más fácil será predecir el resultado que se obtendrá. Cada módulo, tanto UI, base de datos, conexión API Rest, etc., debe poder probarse individualmente.
Interfaz de usuario (UI) independiente
Uno de los componentes que sufre cambios constantes es la interfaz de usuario. La interfaz de usuario debe poder cambiar sin interrumpir todo el sistema. Si vamos más allá, esta capa debería vivir de forma tan independiente como para ser desmontada y sustituida por otra. Por ejemplo, poder cambiar una UI móvil por una en modo consola.
Base de datos independiente
Al igual que en el punto anterior, esta capa debe ser tan modular como para agregar múltiples fuentes de datos e incluso múltiples fuentes del mismo tipo de datos. Por ejemplo, manejar varias bases de datos como MySQL, PostgreSQL, Redis, etc.
Independiente de cualquier elemento externo
Si en algún punto de su sistema necesita una biblioteca, otro sistema o cualquier elemento para conectar, debe ser fácil de ensamblar y modular. De hecho, para el sistema, esta capa exterior debería ser transparente.
Criterios para escoger una arquitectura limpia
- Proyecto de largo aliento
- Que pueda probarse el sistema con facilidad
- Que el sistema requiera una alta tolerancia al cambio
- Minimizar el impacto de los cambios en el sistema
¿Con qué lenguajes de programación puede implementarse una arquitectura limpia?
Básicamente con cualquier lenguaje de programación: Java, .NET, Node.js, Python, etc.-
Aproximación a Domain-Driven Design (DDD)
Las arquitecturas limpias encajan muy bien con el enfoque de diseño basado en dominios (DDD). Cuando nuestro código está en armonía con el modelo de negocios subyacente estamos en presencia de DDD. El objetivo de DDD es diseñar sistemas de software que se basen en el dominio del modelo de negocios.
El patrón DDD es un tema muy amplio (y es imposible cubrirlo en detalle) pero es importante entender que la arquitectura limpia encaja bastante bien con DDD.
¿Puedo utilizar Clean Architectura con algún método ágil de construcción de software?
Si lo que deseamos es construir un MVP para validar nuestro producto probablemente no nos sirva el enfoque de Clean Architecture debido al tiempo de implementación, tomará demasiado tiempo y va a requerir de costos y esfuerzos innecesarios. Si ya validamos el producto con un MVP y queremos llevarlo a un desarrollo más potente y escalable ahí sí podríamos usarlo y nos ayudaría bastante.
Capas de una arquitectura limpia
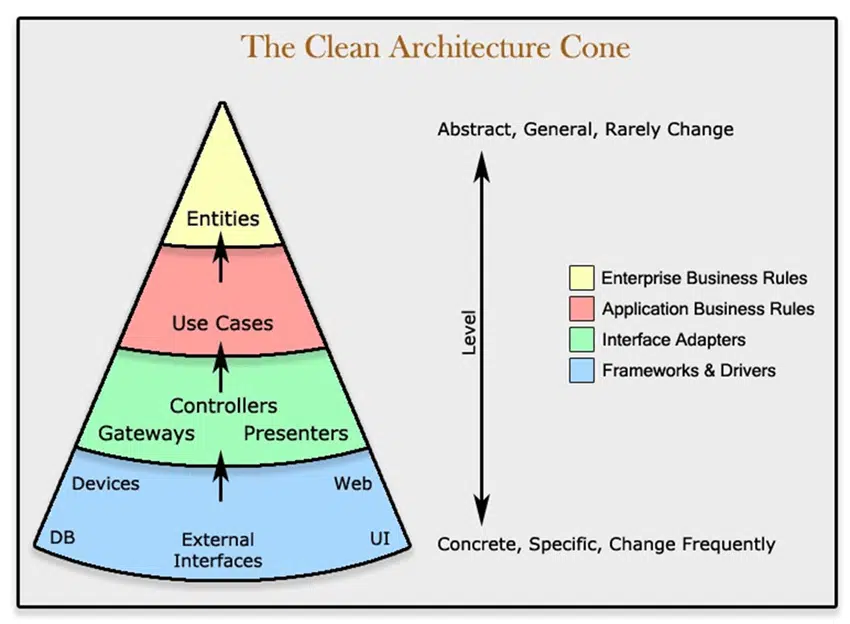
Entities
Las entidades encapsulan las reglas comerciales de toda la empresa. Una entidad puede ser un objeto con métodos o puede ser un conjunto de funciones y estructuras de datos. No importa, siempre y cuando las entidades puedan ser utilizadas por muchas aplicaciones diferentes en la empresa.
Si no tiene una empresa y solo está escribiendo una sola aplicación, estas entidades son los objetos comerciales de la aplicación. Encapsulan las reglas más generales y de alto nivel. Son los menos propensos a cambiar cuando algo externo cambia. Por ejemplo, no esperaría que estos objetos se vieran afectados por un cambio en la navegación de la página o la seguridad. Ningún cambio operativo en ninguna aplicación en particular debería afectar la capa de entidad.
Casos de uso
El software de esta capa contiene reglas comerciales específicas de la aplicación. Encapsula e implementa todos los casos de uso del sistema. Estos casos de uso organizan el flujo de datos hacia y desde las entidades, y dirigen a esas entidades para que utilicen sus reglas de negocios en toda la empresa para lograr los objetivos del caso de uso.
No esperamos que los cambios en esta capa afecten a las entidades. Tampoco esperamos que esta capa se vea afectada por cambios en las externalidades, como la base de datos, la interfaz de usuario o cualquiera de los marcos comunes. Esta capa está aislada de tales preocupaciones.
Sin embargo, esperamos que los cambios en el funcionamiento de la aplicación afecten los casos de uso y, por lo tanto, el software en esta capa . Si los detalles de un caso de uso cambian, entonces parte del código de esta capa se verá afectado.
Adaptadores de interfaz
El software en esta capa es un conjunto de adaptadores que convierten datos del formato más conveniente para los casos de uso y entidades, al formato más conveniente para alguna agencia externa como la Base de Datos o la Web. Es esta capa, por ejemplo, la que contendrá completamente la arquitectura MVC de una GUI. Los presentadores, las vistas y los controladores pertenecen aquí. Es probable que los modelos sean solo estructuras de datos que se pasan de los controladores a los casos de uso, y luego de los casos de uso a los presentadores y vistas.
De manera similar, los datos se convierten, en esta capa, de la forma más conveniente para las entidades y los casos de uso, a la forma más conveniente para cualquier marco de persistencia que se esté utilizando. Es decir, la base de datos. Ningún código dentro de este círculo debería saber nada sobre la base de datos. Si la base de datos es una base de datos SQL, entonces todo el SQL debe estar restringido a esta capa y, en particular, a las partes de esta capa que tienen que ver con la base de datos.
También en esta capa hay cualquier otro adaptador necesario para convertir datos de algún formato externo, como un servicio externo, al formato interno utilizado por los casos de uso y las entidades.
Frameworks y controladores
La capa más externa generalmente se compone de frameworks y herramientas como la base de datos, el framework web, etc. Generalmente, no escribe mucho código en esta capa, aparte del código que se comunica con el siguiente círculo hacia adentro.
Esta capa es donde van todos los detalles. La Web es un detalle. La base de datos es un detalle. Mantenemos estas cosas en el exterior donde pueden hacer poco daño.
¿Solo cuatro círculos?
No, los círculos son esquemáticos. Es posible que descubra que necesita algo más que estos cuatro. No hay una regla que diga que siempre debes tener solo estos cuatro. Sin embargo, siempre se aplica la regla de dependencia. Las dependencias del código fuente siempre apuntan hacia adentro. A medida que te mueves hacia adentro, el nivel de abstracción aumenta. El círculo exterior es un detalle de hormigón de bajo nivel. A medida que avanza hacia el interior, el software se vuelve más abstracto y encapsula políticas de nivel superior. El círculo más interior es el más general.
Cruzando fronteras
En la parte inferior derecha del diagrama hay un ejemplo de cómo cruzamos los límites del círculo. Muestra a los controladores y presentadores comunicándose con los casos de uso en la siguiente capa. Tenga en cuenta el flujo de control. Comienza en el controlador, se mueve a través del caso de uso y luego termina ejecutándose en el presentador. Tenga en cuenta también las dependencias del código fuente. Cada uno de ellos apunta hacia adentro, hacia los casos de uso.
Solemos resolver esta aparente contradicción usando el Principio de Inversión de Dependencia. En un lenguaje como Java, por ejemplo, arreglaríamos las interfaces y las relaciones de herencia de modo que las dependencias del código fuente se opusieran al flujo de control en los puntos justos a lo largo del límite.
Por ejemplo, considere que el caso de uso necesita llamar al presentador. Sin embargo, esta llamada no debe ser directa porque violaría la regla de dependencia: ningún nombre en un círculo externo puede ser mencionado por un círculo interno. Así que tenemos el caso de uso llamando a una interfaz (que se muestra aquí como gateway del caso de uso) en el círculo interior, y el presentador en el círculo exterior lo implementa.
La misma técnica se utiliza para cruzar todos los límites en las arquitecturas. Aprovechamos el polimorfismo dinámico para crear dependencias de código fuente que se oponen al flujo de control para que podamos cumplir con la regla de dependencia sin importar en qué dirección vaya el flujo de control.
Qué datos cruzan los límites
Por lo general, los datos que cruzan los límites son estructuras de datos simples. Puede usar estructuras básicas u objetos simples de transferencia de datos si lo desea (DTO). O los datos pueden ser simplemente argumentos en llamadas a funciones. O puede empaquetarlo en un hashmap o construirlo en un objeto. Lo importante es que las estructuras de datos simples y aisladas se transmiten a través de los límites. No queremos hacer trampa y pasar filas de entidades o bases de datos. No queremos que las estructuras de datos tengan ningún tipo de dependencia que viole la regla de dependencia.
Por ejemplo, muchos frameworks de bases de datos devuelven un formato de datos conveniente en respuesta a una consulta. Podríamos llamar a esto una RowStructure. No queremos pasar esa estructura de filas hacia adentro a través de un límite. Eso violaría la Regla de la Dependencia porque obligaría a un círculo interno a saber algo sobre un círculo externo.
Entonces, cuando pasamos datos a través de un límite, siempre es en la forma más conveniente para el círculo interior.
Conclusión
Cumplir con estas reglas simples no es difícil y nos ahorrará muchos dolores de cabeza en el futuro. Al separar el software en capas y cumplir con la regla de dependencia, crearemos un sistema que es intrínsecamente comprobable, con todos los beneficios que ello implica. Cuando alguna de las partes externas del sistema se vuelve obsoleta, como la base de datos o el framework web (por ejemplo cambiar de Angular a React), podemos reemplazar esos elementos obsoletos con un mínimo de esfuerzo.